
「学習データ品質管理」ページは、AIエージェントに登録するナレッジデータの中に、
機密情報や公開が望ましくない情報が含まれていないかを自動でスクリーニングする機能です。
すべてのナレッジを手作業で確認することが難しい現実を踏まえ、
セキュリティと品質を両立させるための自動チェック機構として活用いただけます。
 学習データの検出オプション
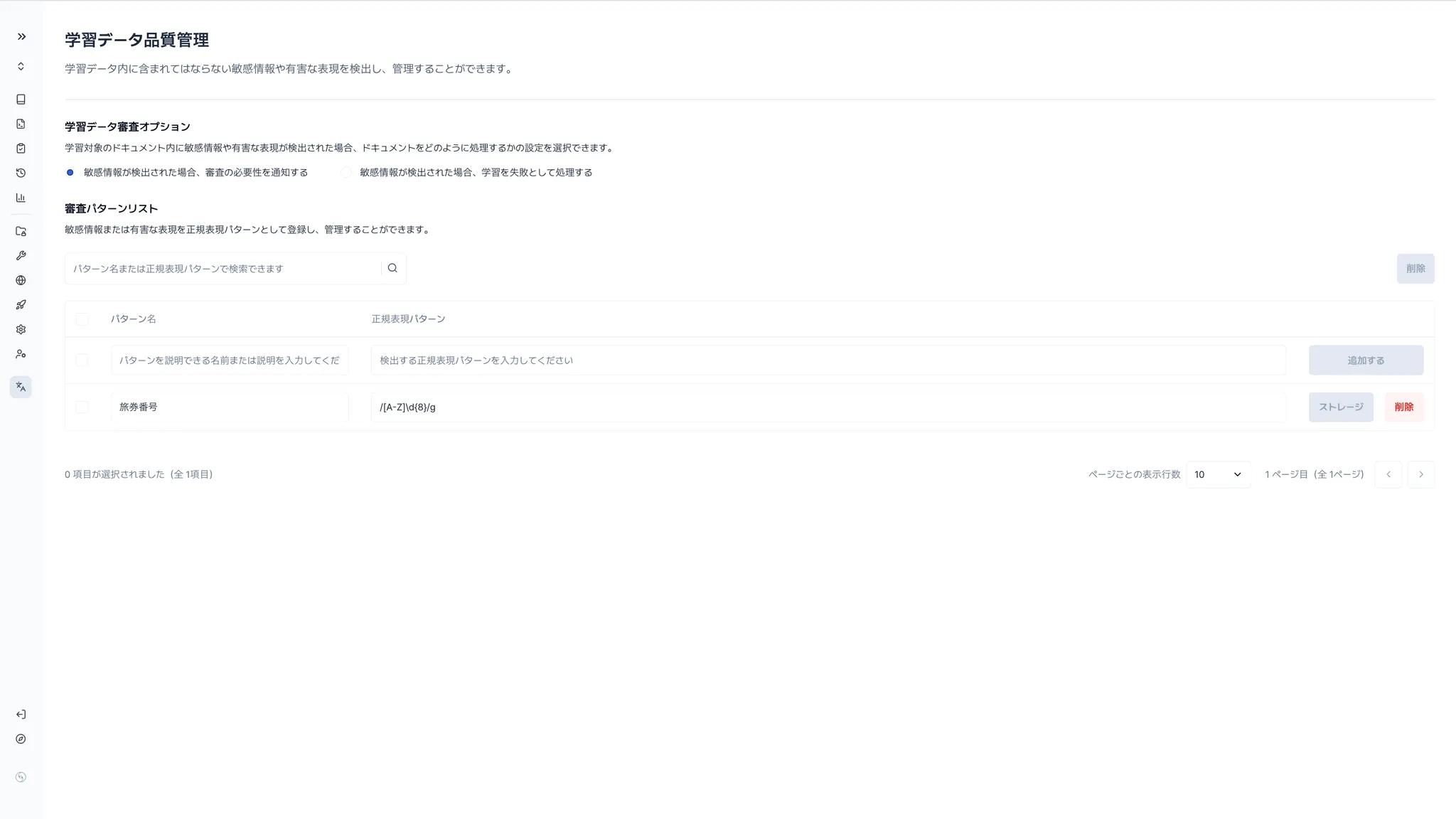
学習データの検出オプション
学習前にナレッジ内の機密情報を検出した場合の動作方針を以下の2つから選択できます:
① 「確認が必要」として処理
•
学習はそのまま継続されます。
•
該当箇所は「確認が必要な項目」として管理者に通知され、後から確認・対応可能です。
•
通常の業務フローを止めずに、後追いで精査したい場合に適しています。
② 「学習失敗」として処理
•
検出された時点で、**該当ナレッジの学習は中断(=失敗)**されます。
•
セキュリティ要件が高いチーム・業務用エージェントでは、こちらのオプションの使用が推奨されます。
検出パターンリストの設定
ナレッジの中で検出すべき情報パターンを、以下の形式で登録します:
項目 | 内容 |
パターン名 | 検出する機密情報の分類名を分かりやすく設定(例:顧客電話番号, 社外秘プロジェクト名 など) |
正規表現パターン | 検出条件を記述する**正規表現(Regex)**形式で設定します |
結果の確認方法
•
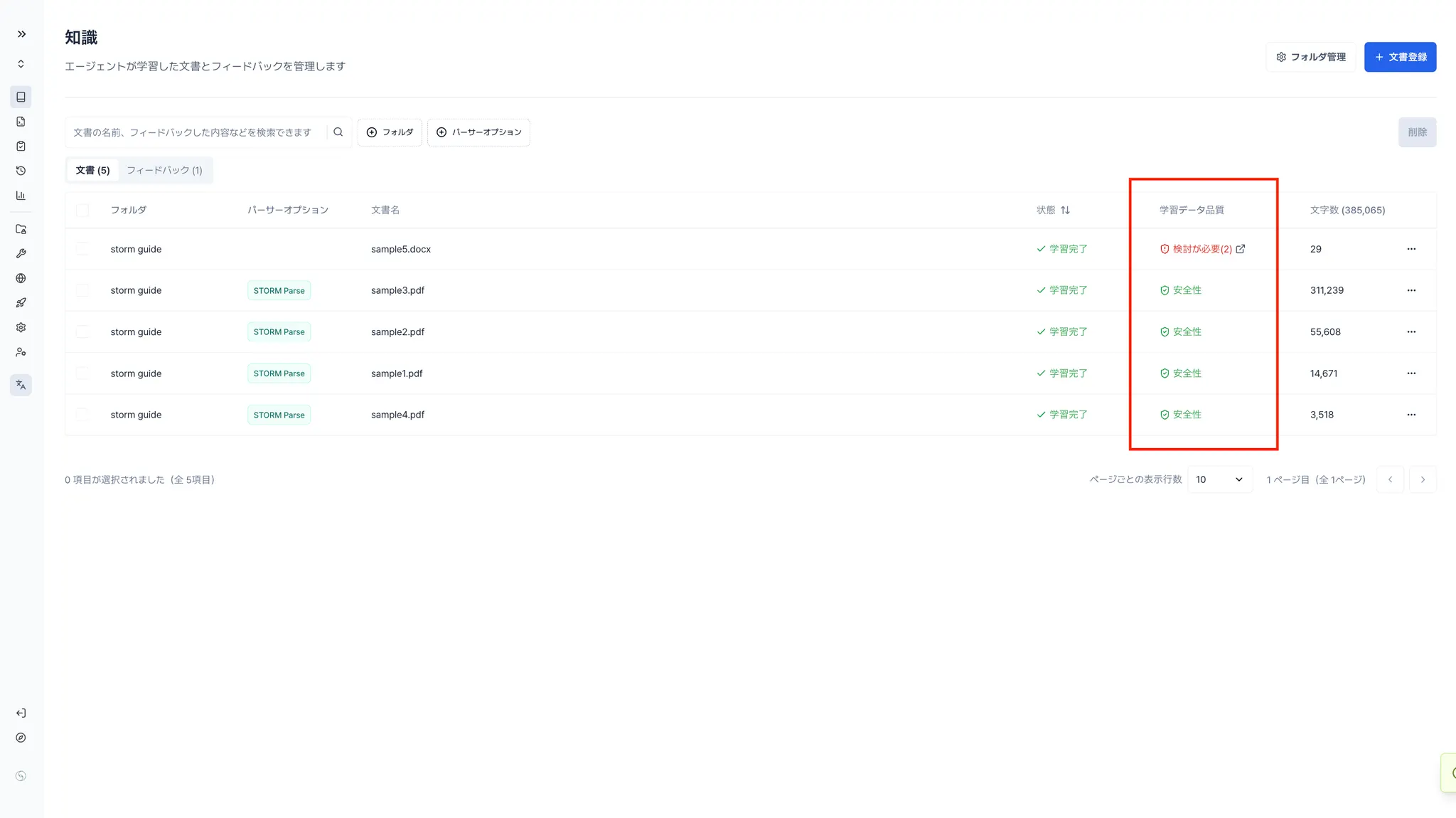
登録したパターンに該当する内容が検出された場合、該当ナレッジは一覧上の**「学習データ品質」列にフラグ表示**されます。
•
管理者はそこから該当箇所の確認・差し替え・除外などの対応を行うことができます。
この機能のメリット
•
ナレッジ登録の自動安全チェックが可能になるため、作業負荷を下げながらセキュリティレベルを維持できます。
•
企業の情報管理基準に応じて柔軟に検出ルールを追加・変更でき、運用の実情にフィットした管理が可能です。
ご希望に応じて、正規表現の記述サンプルや、セキュリティポリシーに基づく推奨パターン例もご案内可能です。お気軽にご相談ください。